This post focuses on Optical Character Recognition (OCR) as a resource for digital accessibility. For more on digital accessibility at UChicago, please visit the Center for Digital Accessibility (CDA), and consider registering for the upcoming workshop “Accessibility in Teaching: Effective Practices,” to be held on 9 November 2021.
For some instructors, the emergency transition to remote teaching in March 2020 represented the first occasion in their careers on which they wrestled with considerations of digital accessibility. However, for many University faculty, staff, and especially students, matters of digital accessibility are part and parcel of the daily experience of teaching and learning – forming barriers to attendance and engagement for some, posing logistical and pedagogical challenges for active learning activities that make use of digital tools, and affecting different individuals in vastly different (and unequally distributed) ways. In this blog post, we will consider the multifaceted uses of Optical Character Recognition (OCR) for optimizing the accessibility and flexibility of PDF-based course materials and activities. We will explore both the positive impact OCR can have for students with disabilities and the more expansive range of engagement options OCR can make possible for all learners. In keeping with the principle of Universal Design for Learning, we will suggest a mindset and workflow for stewarding more accessible PDFs and facilitating more engaged and accessible class activities that draw upon a range of OCR resources.
While OCR refers broadly to the process of converting scanned documents and textual materials into text that is readable, recognizable, and selectable by the computer, assistive software programs, or end users, its affordances are multidimensional. For students who rely on screen readers and other assistive technologies, OCR processing makes the scan of a document usable – transforming it from an image capture of a text to a document composed of recognized strings of text. For instructors who make use of digital annotation in their teaching, OCR is a necessary first step, both for purposes of digital accessibility and out of technological necessity, as most digital annotation programs require PDFs with selectable as well as searchable text. OCR thus has a foundational importance both for digital accessibility (also rendered as digital a11y) and for broadening opportunities for close textual engagement with a digital annotation tool such as Hypothes.is.
Mindset and Practice: “From this point forward…”
As Keith Bundy observes, it can be overwhelming to approach the task of making all existing PDFs accessible – at least, when we imagine taking on that task in a single sitting. But as Bundy reminds us: “Yes, all PDFs have to be accessible, but not by midnight tonight.” Instead of working frantically to perform OCR optimization on every PDF you can find on your file system, we encourage you to shift your mindset going forward and to work backward selectively and incrementally. In changing your future-facing mindset, this entails deciding that, from this day forward, you will put every new PDF you generate and receive through OCR processing. To work backward in a focused way, you can pick a specific point in the past (e.g. September of 2018), and gradually work your way through PDFs you use for instructional purposes, performing OCR processing on these materials gradually.
There are several advantages to working toward optimal PDF accessibility in this bidirectional manner – not the least of which is the manageable, incremental effort it requires when working through existing materials! Most importantly, however, producing accessible, OCR-processed PDFs as you move forward represents a meaningful commitment to digital accessibility that you can make to support your students, TAs and course staff members, and colleagues.
Tip #1: Generate from Word Processor
One of the quickest ways to produce an accessible PDF with effective character recognition is to generate the document from a word processor. For example, if you were to ask your students to engage with the transcript of a public radio interview, with a particular work of modernist poetry, or with song lyrics in the new language students are learning, you could quickly and easily produce an accessible PDF by copying over or transcribing text into (e.g.) a Microsoft Word document, then saving that file as a PDF. When using this strategy, it is crucial to save the word processing file as a PDF rather than “printing” a PDF. (When a word processing application or file system “prints” rather than “saves” a PDF, an image is taken of the document – the very opposite of what we seek.)
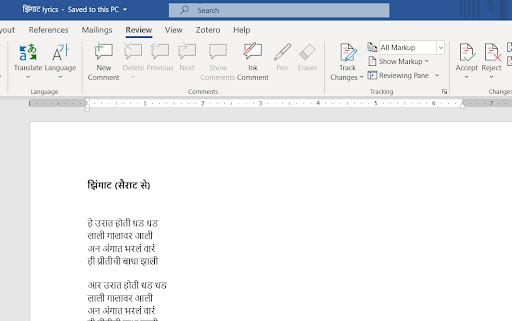
Marathi-language text (Devanagari script) created in Microsoft Word
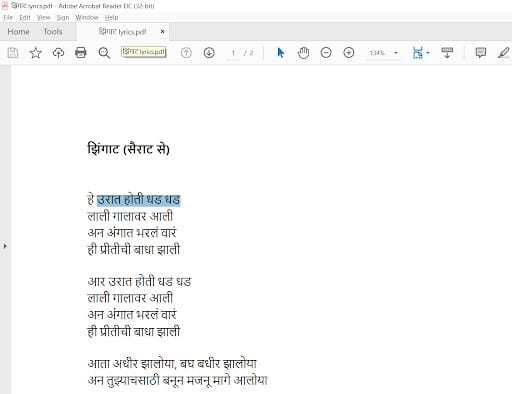
OCR-optimized PDF version created by saving PDF from Word
Instructors working with languages other than English, non-Roman alphabets, or texts that make considerable use of diacritical marks often find this strategy to be particularly useful, as it sidesteps the necessity of locating an OCR tool compatible with the particular language or alphabet of instruction.
Tip #2: Producing a Clean, Well-Aligned Scan
When creating an electronically available document for student use from a physical book, object, or artifact, taking the time to produce as clean and – particularly – as well-aligned a scan as possible can make a terrific difference in the effectiveness of subsequent OCR optimization. To the extent possible, align the text within the frame of your scanner (whether a multifunction copier, scanning app on a smartphone camera, or tablet) such that page margins are parallel to the extreme boundaries of the scanner’s viewfinder or frame. Similarly, as far as possible with the resources of your scanning apparatus, bring the text into focus. Whatever kind of scanner you are using, strive to avoid casting any shadows on the text by adjusting your position relative to light sources. Finally, if you have access to multiple settings on your scanner, we suggest using the following specifications: 300dpi (dots per inch); grayscale; and .tiff or .jpeg when saving in an image format.
Tip #3: Use an OCR Utility on a Scanned PDF
Once you have produced a well-aligned scan of a physical material, locate and utilize an appropriate Optical Character Recognition optimization utility. UChicago provides access to SensusAccess, which supports all languages that use the Roman alphabet as well as several that do not. To use this utility, upload your file to the UChicago SensusAccess portal, select the output format (Accessibility conversion), and specify the conversion format (Tagged PDF – text over image). You will receive the OCR-optimized output by email when processing is complete. Full documentation on using SensusAccess for accessibility conversion is maintained by Academic Technology Solutions (ATS). (One caveat: SensusAccess has a file size limit of approximately 50 MB. If your file is larger than this, you may find it necessary to split it into smaller documents before beginning OCR.)
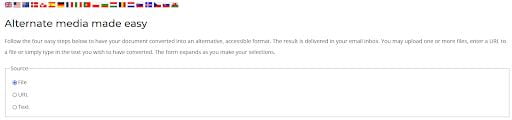
Web portal for SensusAccess OCR utility: uploading file to be processed
Numerous free OCR tools are available on the web. One such tool, Doc Drop, works with additional non-Roman alphabets, including numerous South Asian, East Asian, and Southeast Asian scripts. You can also access several open-access OCR utilities designed for use with specific alphabets, including SanskritCR for Devanagari and i2OCR for Arabic.
Finally, some University instructors and staff who make frequent use of OCR, or who do so across languages, prefer subscription-based PDF configuration utilities, including Adobe Acrobat and Abbyy FineReader. You can consult your academic unit about any utilities currently in use, and you can always contact Academic Technology Solutions for help in identifying an appropriate OCR utility.
Tip #4: When You Hit a Wall
Sometimes, especially when an instructional material comes to us from an archival source or rare or out-of-print book, we hit a wall with respect to the effectiveness of OCR utilities. In these cases, when OCR processing either does not produce effectively recognized and accessible text or goes haywire when encountering an unclear scan (as pictured in an extreme example below), we suggest two pathways forward when you are unable to create a new scan of your material. First, if your source exists in print in another library, consider placing a Scan and Deliver or Interlibrary Loan request for the material, or getting in touch with your subject-area librarian for assistance. Second, if your material is not available in other libraries (e.g. an archival artifact), please get in touch with ATS and we will attempt to assist you in cleaning up your document scan to the extent possible. When reaching out, please share your document, its use (instructional or research), and, if applicable, whether you plan to use it with Hypothes.is.

Poorly aligned and illuminated scan rendered illegible by OCR utility
Further Resources
-
- “Making Accessible PDFs” webinar, SiteImprove. Hosted by Accessibility Community Consultant Keith Bundy, this hour-long webinar provides an introduction to PDF accessibility optimization.
- “Creating Accessible PDFs” course, LinkedIn Learning. This comprehensive course (accessible to University community members after authenticating with CNetID) is intended for sighted content creators and stewards and covers several critical accessibility areas, including: (i) accessibility remediation of existing PDFS, (ii) creating new accessible PDFs from word processors, and (iii) the user experience of a screenreader encountering accessible and inaccessible PDFs.
- SensusAccess OCR tool. This OCR tool is supported by Academic Technology Solutions.
- DocDrop OCR tool.
References Cited
Academic Technology Solutions. “Expanded Student Annotation Assignment Options in Canvas.” University of Chicago. 21 June 2021. Accessed 25 October 2021.
Academic Technology Solutions. “Recommended Settings and Step-by-Step SensusAccess Guide.” Accessed 25 October 2021.
American Foundation for the Blind. “Optical Character Recognition Systems.” 2020. Accessed 25 October 2021.
Center for Digital Accessibility. “What is digital accessibility?” 2021. Accessed 25 October 2021.
eLearning Office. “Optical Character Recognition (OCR).” Gies College of Business, University of Illinois. 9 August 2017. Accessed 25 October 2021.
Hypothes.is. “How to OCR-optimize PDFs.” 2021. Accessed 25 October 2021.
“PDF Scanning and Optical Character Recognition.” Digital Accessibility at the University of Oregon. Accessed 25 October 2021.
Image Credit
Vectorified. “Build an Inclusive Website with Digital Accessibility.” Web Accessibility Icon.
{kind=link}